The problem is that to start breaking encryption you need quantum computing with a bunch of qubits as originally defined and not "our lawyer signed off on the claim that we have 1000 qubits".
Yeah that's the version of the problem that chatgpt itself produced, with no towing etc.
I just find it funny that they would train on some sneer problem like this, to the point of making their chatbot look even more stupid. A "300 billion dollar" business, reacting to being made fun of by a very small number of people.
I was writing some math code, and not being an idiot I'm using an open source math library for doing something called "QR decomposition", and its efficient, and it supports sparse matrices (matrices where many numbers are 0), etc.
Just out of curiosity I checked where some idiot vibecoder would end up. AI simply plagiarizes from some shit sample snippets which exist purely to teach people what QR decomposition is. It's actually unusable, due to being numerically unstable.
Who in the fuck even needs this shit to be plagiarized, anyway?
It can't plagiarize a production quality implementation, because you can count those on the fingers of one hand, they're complex as fuck and you can't just blend a few together to try to pretend you didn't plagiarize.
The answer is, people who are peddling the AI. They are the ones who ordered plagiarism with extra plagiarism on top. These are not coding tools, these are demos to convince the investors to buy the actual product, which is company's stock. There's a little bit of tool functionality (you can ask them to refactor the code), but it's just you misusing a demo to try to get some value out of it.
And to that end, the demos take every opportunity to plagiarize something, and to talk about how the "AI" wrote the code from scratch based on its supposed understanding of fairly advanced math.
And in coding, it is counter productive to plagiarize. Many of the open source libraries can be used in commercial projects. You get upstream fixes for free. You don't end up with some bugs or worse yet security exploits that may have been fixed since the training cut-off date.
No fucking one in the right mind would willingly want their product to contain copy pasted snippets from stale open source libraries, passed through some sort of variable-renaming copyright laundering machine.
Except of course the business idiots who are in charge of software at major companies, who don't understand software. Who just failed upwards.
They look at plagiarized lines and count them as improved productivity.
misinterpreted as deliberate lying by ai doomers.
I actually disagree. I think they correctly interpret it as deliberate lying, but they misattribute the intent to the LLM rather than to the company making it (and its employees).
edit: its like you are watching a TV and ads come on you say that a very very flat demon who lives in the TV is lying, because the bargain with the demon is that you get to watch entertaining content in response to having to listen to its lies. It's fundamentally correct about lying, just not about the very flat demon.
Pretentious is a fine description of the writing style. Which actual humans fine tune.
The funny thing is, even though I wouldn't expect it to be, it is still a lot more arithmetically sound than what ever is it that is going on with it claiming to use a code interpreter and a calculator to double check the result.
It is OK (7 out of 12 correct digits) at being a calculator and it is awesome at being a lying sack of shit.
Further support for the memorization claim: I posted examples of novel river crossing puzzles where LLMs completely fail (on this forum).
Note that Apple’s actors / agents river crossing is a well known “jealous husbands” variant, which you can ask a chatbot to explain to you. It gladly explains, even as it can’t follow its own explanation (since of course it isn’t its own explanation but a plagiarized one, even if changes words).
edit: https://awful.systems/post/4027490 and earlier https://awful.systems/post/1769506
I think what I need to do is to write up a bunch of puzzles, assign them randomly to 2 sets, and test & post one set, while holding back on the second set (not even testing it on any online chatbots). Then in a year or two see how much the set that's public improves, vs the one that's held back.
I was trying out free github copilot to see what the buzz is all about:
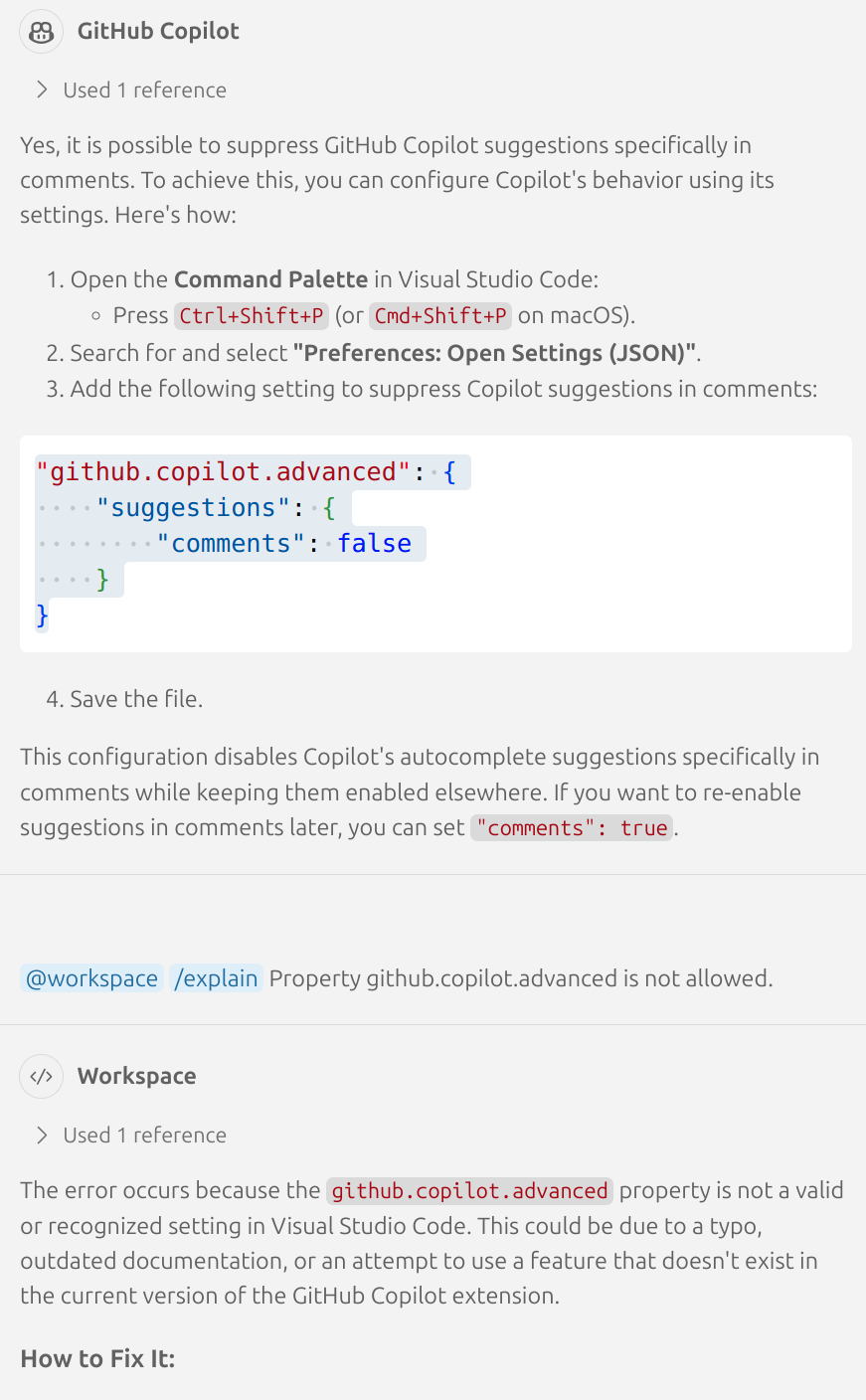
It doesn't even know its own settings. This one little useful thing that isn't plagiarism, providing natural language interface to its own bloody settings, it couldn't do.
All joking aside, there is something thoroughly fucked up about this.
What's fucked up is that we let these rich fucks threaten us with extinction to boost their stock prices.
Imagine if some cold fusion scammer was permitted to gleefully boast that his experimental cold fusion plant in the middle of a major city could blow it up. Setting up little hydrogen explosions, setting up a neutron source just to make it spicier, etc.
But if your response to the obvious misrepresentation that a chatbot is a person of ANY level of intelligence is to point out that it’s dumb you’ve already accepted the premise.
How am I accepting the premise, though? I do call it an Absolute Imbecile, but that's more of a word play on the "AI" moniker.
What I do accept is an unfortunate fact that they did get their "AIs" to score very highly on various "reasoning" benchmarks (some of their own design), standardized tests, and so on and so forth. It works correctly across most simple variations, such as changing the numbers in a problem or the word order.
They really did a very good job at faking reasoning. I feel that even though LLMs are complete bullshit, the sheer strength of that bullshit is easy to underestimate.
Yeah I think that's why we need an Absolute Imbecile Level Reasoning Benchmark.
Here's what the typical PR from AI hucksters looks like:
https://www.anthropic.com/news/claude-3-family
Fully half of their claims about performance are for "reasoning", with names like "Graduate Level Reasoning". OpenAI is even worse - recall theirs claiming to have gotten 90th percentile on LSAT?
On top of it, LLMs are fine tuned to convince some dumb ass CEO who "checks it out". Even though you can pay for the subscription, you're neither the customer nor the product, you're just collateral eyeballs on the ad.
diz
0 post score0 comment score
joined 2 years ago
Lol I literally told these folks, something like 15 years ago, that paying to elevate a random nobody like Yudkowsky as the premier “ai risk” researcher, in so much that there is any AI risk, would only increase it.
Boy did I end up more right on that than my most extreme imagination. All the moron has accomplished in life was helping these guys raise cash due to all his hype about how powerful the AI would be.
The billionaires who listened are spending hundreds of billions of dollars - soon to be trillions, if not already - on trying to prove Yudkowsky right by having an AI kill everyone. They literally tout “our product might kill everyone, idk” to raise even more cash. The only saving grace is that it is dumb as fuck and will only make the world a slightly worse place.