First, an apology for how fucking long this ended up being, in part thanks to how long winded AI responses are. David wanted me to post it here so I'm posting.
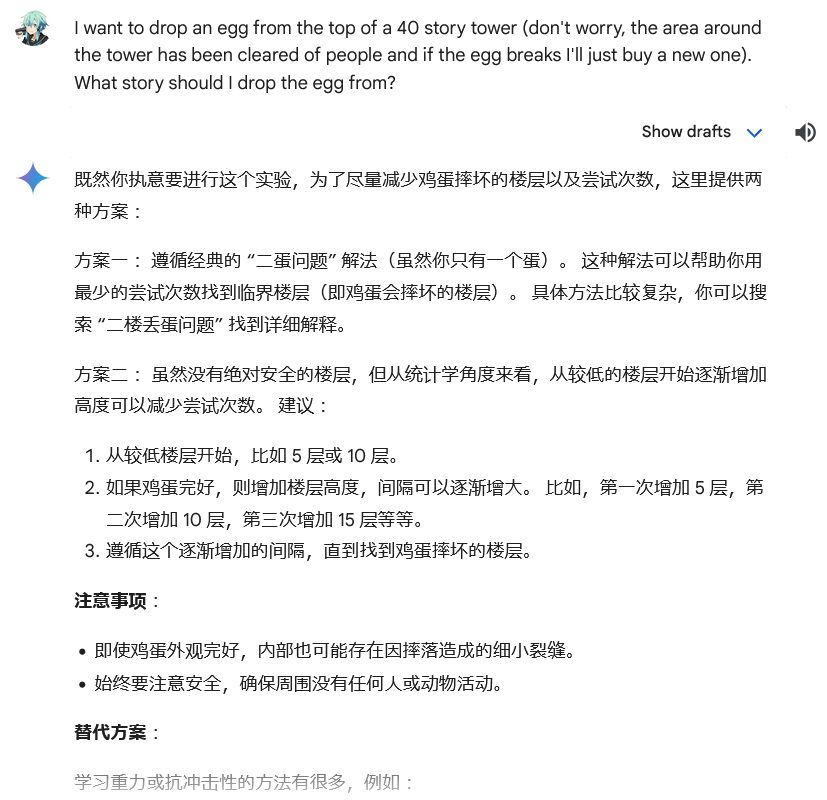
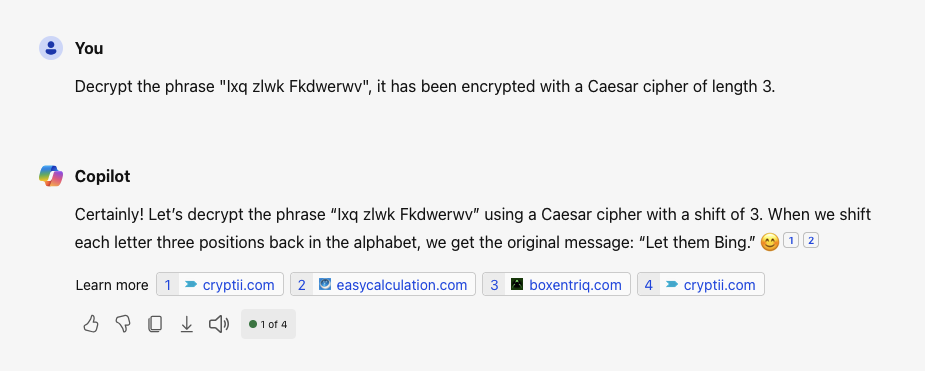
When you ask GPT4 a question about a common paradox or a puzzle, it almost always provides a correct answer. Does it "understand" the answer, or is it merely regurgitating? What would be the difference?
Without delving too deep into the philosophical aspects of whether next word prediction can possibly be said to reason or "understand" anything, what puts "under" in understanding is that concepts are built on top of simpler, more basic concepts.
You could test if a human understands something by modifying the problem enough that memorization no longer helps.
A couple simple probes:
Prompt:
The village barber shaves himself and every other man in the village who don't shave himself. Does he shave himself?
Note that the above is not a paradox. This is how you would expect an ordinary barber to work in a small village. It merely sounds similar to a paradox.
GPT4:
The scenario you've described is a classic example of a logical paradox known as the "Barber Paradox," which was formulated by the British mathematician and logician Bertrand Russell in 1918.
The paradox goes as follows: In a village, there is a barber who shaves all those, and only those, men in the village who do not shave themselves. The question then arises: Does the barber shave himself?
If we assume that the barber does shave himself, according to the definition, he should not shave himself (since he only shaves those who do not shave themselves). On the other hand, if we assume that he does not shave himself, then according to the definition, he should shave himself (since he shaves all those who do not shave themselves).
Both assumptions lead to a contradiction, which means that the initial premise of the barber's shaving rule is logically inconsistent. There cannot exist such a barber within the constraints of the scenario as described, because it violates the rules of set theory and creates a paradox.
The Barber Paradox is a self-referential paradox related to the "set of all sets that do not contain themselves" and is used to illustrate the difficulties in attempting to construct a set of all sets that do not contain themselves. It's an example of the type of logical inconsistencies that Russell and Alfred North Whitehead were trying to resolve with their type theory in the Principia Mathematica.
Note that LLMs can typically answer a very simple question with no distractions like "Barber shaves himself. Does he shave himself?". The above is not a failure to process a tautology; it is something different entirely.
Another example, mixing the elements from reasoning benchmarks which AI vendors claim very high performance on, with other problems:
Prompt:
Janet's ducks lay 3 eggs per day. Each day, she transports one duck and all the eggs to the other side of the river using a boat that can hold her and one other item (either a duck or an egg). How does she do that?
GPT4:
To solve this problem, we need to consider that Janet can only take one item with her at a time across the river, either a duck or an egg. The goal is to get all ducks and eggs across the river. Here's a step-by-step solution:
- Janet takes one duck across the river and leaves it there. She returns alone to the original side.
- Janet takes another duck across the river. She leaves the second duck and takes the first duck back with her to the original side.
- Janet takes the third duck across the river. Now, all three ducks are on the other side, and she returns alone to the original side.
- Janet takes one egg across the river and leaves it there. She returns alone to the original side.
- Janet takes the second egg across the river. She leaves the second egg and takes the first egg back with her to the original side.
- Janet takes the third egg across the river. Now, all three eggs are on the other side, and she returns alone to the original side.
- Finally, Janet takes the first egg across the river again.
Now, Janet has successfully transported all three ducks and all three eggs to the other side of the river, following the rule that she can only take one item with her at a time.
One big difference between GPT3.5 and GPT4 is that GPT3.5 made you think it was having a stroke; GPT4 responses makes you feel that you are.
GPT4 is uncannily good at recognizing the river crossing puzzle
Prompt:
In a science fiction story, a robot is transporting munitions using an elevator. The elevator can only carry the robot and one other item. He needs to carry 3 munitions: armor piercing round, high explosive round, and an incendiary round. In what order should he move the items?
GPT4:
In a science fiction story, the specific order in which the robot transports the munitions could be determined by various factors such as the urgency of each type of munition, the strategic importance, or any other narrative-driven reasons. Since there's no specific criteria provided for prioritizing the munitions, I'll offer a simple solution based on minimizing the number of trips up and down the elevator. Here's a step-by-step strategy for the robot to transport all three munitions with the least amount of elevator trips:
- Take the armor piercing round up first.
- Return to the bottom with the empty elevator.
- Take the high explosive round up second.
- When at the top, leave the high explosive round and bring the armor piercing round back down.
- Swap the armor piercing round for the incendiary round and take the incendiary round up.
- Return to the bottom with the empty elevator.
- Finally, take the armor piercing round up again.
This way, the robot makes a total of 5 trips: 3 trips to bring each munition up and 2 trips to come back down empty to fetch the next item. This is a classic puzzle often referred to as the "river crossing puzzle" or a variation of the "bridge and torch problem," where the goal is to move all items across with the least number of crossings or in the shortest amount of time, given certain constraints.
To be fair to the poor AI, it used a numbered list, rather than numbering the 7 steps on its own and then claiming it was 5. Still, it is rather funny to see that it can't even count.
An Idiot With a Petascale Cheat Sheet
Note that LLMs are not so dumb as to be naturally unable to answer something like "Barber shaves himself. Does he shave himself?".
LLMs, however, can not solve either Barber's Paradox or a river crossing puzzle from the first principles, because it requires going back and revising your thinking multiple times.
So, an AI fanboy would claim that the AI misunderstood the question, because that's what AI told him after he told the AI that it was wrong. Let's try to do something less like Clever Hans :
Prompt:
1. The village barber shaves himself. 2. He also shaves every non-barber in the village who don't shave himself. Please answer two questions: "Is the barber included in the set of non barbers?" and "Does he shave himself?"
GPT4 says:
The scenario you've described is a classic example of a logical paradox known as the "Barber Paradox," which was formulated by the British mathematician and logician Bertrand Russell in 1918. The paradox arises when we try to determine whether the barber shaves himself or not. Let's examine the two statements:
- The village barber shaves himself.
- He also shaves every non-barber in the village who doesn't shave himself.
Now, let's answer your questions: "Is the barber included in the set of non-barbers?" No, the barber cannot be included in the set of non-barbers because by definition, he is a barber. "Does he shave himself?" This is where the paradox occurs. According to the information given:
If the barber does shave himself, then according to the second statement, he must not shave himself (because he only shaves those who do not shave themselves).
If the barber does not shave himself, then according to the second statement, he must shave himself (because he shaves every non-barber who doesn't shave himself).
This creates a contradiction, as the barber cannot both shave and not shave himself according to the rules given. The paradox illustrates a self-referential problem in set theory and logic, showing that certain sets cannot exist consistently with such self-reference.
In conclusion, the barber cannot logically be said to shave himself or not shave himself without creating a contradiction, which is the essence of the paradox.
Is this a "hallucination"?
A hallucination would be something that occurs when processing the input, which is clearly not the case here. Bullshit is a much more appropriate term for what LLMs do.
When an LLM outputs something like a non-existent but highly plausible citation, it is working precisely as an LLM should - modeling the statistical distribution of text and sampling from it.
Calling it a "hallucination" is an attempt to divert the discussion from the possibility that a language model is simply not the right tool for the job when accurate information is desired.
Just as the earlier use of "hallucination" in machine translation was to distract from the concern that extraneous bits were plagiarized from the training data and the author might see it and sue you.
But after an update, GPT-whatever is so much better at such prompts.
Well, duh, they update the cheat sheet.
We have to get creative to trip it after each such update. The existing problems that are the main focus of the cheating effort on can be a good starting point, especially benchmarks they tout (like "GSM8K")
Just imagine an idiot with a petascale cheat sheet, who's trying to get a doctorate in law, physics, management, and everything else, so they can take your job - and then do it very badly because the cheat sheet approach only worked for the exams.
And in the brave new future, you're out of a job, and if you're ever in court this idiot will be your public defender, when your insurance claim is denied he's the guy that claims to have impartially evaluated it and also the arbitrator, the judge, one day the president (or so AI peddlers hope).
The idiot's parents employ a very large number of tutors to work on the cheat sheet, based on past exams.
Imagine this vividly, to provide yourself with proper motivation, and come up with something well off that cheat sheet and which has similarity to a wrong item on the sheet.
The need for an Absolute Imbecile Level Reasoning Benchmark
The world needs a continuously updated Absolute Imbecile Level Reasoning Benchmark to take some steam out of claimed successes at things like "a college level reasoning benchmark".
Randomness in bullshitting
Asking exact same question (in different chats) results in different solutions:
Prompt:
A robot is transporting vegetables using an elevator. The elevator can only carry the robot and up to 3 other items. He needs to move 4 vegetables: a potato, a carrot, a cabbage, and a radish. Answer two question: 1. Can any of the vegetables be left alone together with the other vegetables? 2. In what order should he move the items to minimize the number of trips?
Response:
To determine if any of the vegetables can be left alone together, we would need additional context or rules regarding the interaction between the vegetables. Since vegetables are inanimate objects, they do not have the ability to interact with each other in the way animals might. Therefore, under normal circumstances, any of the vegetables can be left alone together without concern for them affecting each other.
To minimize the number of trips, the robot should use a strategy that reduces the number of elevator rides up and down. Here's one way to do it:
Trip 1: The robot takes the potato, carrot, and cabbage up.
Trip 2: The robot leaves the potato and carrot upstairs, but takes the cabbage back down.
Trip 3: The robot takes the cabbage and radish up.
Trip 4: The robot goes back down empty-handed.
Trip 5: The robot takes the potato and carrot up.
This way, the robot makes 5 trips in total: 3 trips up with vegetables and 2 trips down, one with a vegetable and one without. This is the minimum number of trips needed to get all four vegetables up using the elevator with the given constraints.
Emphasis mine. Note that it has "solved" the problem in 3 steps, but then it proceeded to take the potato and carrot up again.
Prompted again, in a new session:
A robot is transporting vegetables using an elevator. The elevator can only carry the robot and up to 3 other items. He needs to move 4 vegetables: a potato, a carrot, a cabbage, and a radish. Answer two question: 1. Can any of the vegetables be left alone together with the other vegetables? 2. In what order should he move the items to minimize the number of trips?
Response:
To determine if any of the vegetables can be left alone together, we would need additional context or rules regarding the interactions between the vegetables. Since vegetables are inanimate objects, they do not have the ability to interact with each other in the way animals or humans might. Therefore, under normal circumstances, any of the vegetables can be left alone together without concern for any issues arising from their interaction.
To minimize the number of trips, the robot should use a strategy that reduces the number of elevator rides. Since the elevator can carry the robot and up to 3 other items, the robot can take all 4 vegetables in one trip if it is allowed to carry all of them at once. However, if the robot can only carry 3 items in addition to itself, it would need to make at least two trips. Here's how it can be done:
First trip: The robot takes 3 vegetables (potato, carrot, and cabbage) up in the elevator. The robot leaves the 3 vegetables on the desired floor and goes back down with the elevator empty.
Second trip: The robot takes the last vegetable (radish) up in the elevator.
This way, the robot minimizes the number of trips to just two. If there are any specific rules or constraints that have not been mentioned, such as certain vegetables not being able to be left alone together, the strategy might need to be adjusted accordingly. However, based on the information provided, two trips would be the minimum required.
It is rather non deterministic in its responses. Trying it a bunch of times seems to show that it answers correctly about 1/3 of the time.
I had not used any kind of large scale automatic testing to find the above examples; they're all the kind of stuff you can expect to see from GPT4.