I want to apologize for changing the description without telling people first. After reading arguments about how AI has been so overhyped, I'm not that frightened by it. It's awful that it hallucinates, and that it just spews garbage onto YouTube and Facebook, but it won't completely upend society. I'll have articles abound on AI hype, because they're quite funny, and gives me a sense of ease knowing that, despite blatant lies being easy to tell, it's way harder to fake actual evidence.
I also want to factor in people who think that there's nothing anyone can do. I've come to realize that there might not be a way to attack OpenAI, MidJourney, or Stable Diffusion. These people, which I will call Doomers from an AIHWOS article, are perfectly welcome here. You can certainly come along and read the AI Hype Wall Of Shame, or the diminishing returns of Deep Learning. Maybe one can even become a Mod!
Boosters, or people who heavily use AI and see it as a source of good, ARE NOT ALLOWED HERE! I've seen Boosters dox, threaten, and harass artists over on Reddit and Twitter, and they constantly champion artists losing their jobs. They go against the very purpose of this community. If I hear a comment on here saying that AI is "making things good" or cheering on putting anyone out of a job, and the commenter does not retract their statement, said commenter will be permanently banned. FA&FO.

cross-posted from: https://lemm.ee/post/66544085
Text to avoid paywall
The Wikimedia Foundation, the nonprofit organization which hosts and develops Wikipedia, has paused an experiment that showed users AI-generated summaries at the top of articles after an overwhelmingly negative reaction from the Wikipedia editors community.
“Just because Google has rolled out its AI summaries doesn't mean we need to one-up them, I sincerely beg you not to test this, on mobile or anywhere else,” one editor said in response to Wikimedia Foundation’s announcement that it will launch a two-week trial of the summaries on the mobile version of Wikipedia. “This would do immediate and irreversible harm to our readers and to our reputation as a decently trustworthy and serious source. Wikipedia has in some ways become a byword for sober boringness, which is excellent. Let's not insult our readers' intelligence and join the stampede to roll out flashy AI summaries. Which is what these are, although here the word ‘machine-generated’ is used instead.”
Two other editors simply commented, “Yuck.”
For years, Wikipedia has been one of the most valuable repositories of information in the world, and a laudable model for community-based, democratic internet platform governance. Its importance has only grown in the last couple of years during the generative AI boom as it’s one of the only internet platforms that has not been significantly degraded by the flood of AI-generated slop and misinformation. As opposed to Google, which since embracing generative AI has instructed its users to eat glue, Wikipedia’s community has kept its articles relatively high quality. As I recently reported last year, editors are actively working to filter out bad, AI-generated content from Wikipedia.
A page detailing the the AI-generated summaries project, called “Simple Article Summaries,” explains that it was proposed after a discussion at Wikimedia’s 2024 conference, Wikimania, where “Wikimedians discussed ways that AI/machine-generated remixing of the already created content can be used to make Wikipedia more accessible and easier to learn from.” Editors who participated in the discussion thought that these summaries could improve the learning experience on Wikipedia, where some article summaries can be quite dense and filled with technical jargon, but that AI features needed to be cleared labeled as such and that users needed an easy to way to flag issues with “machine-generated/remixed content once it was published or generated automatically.”
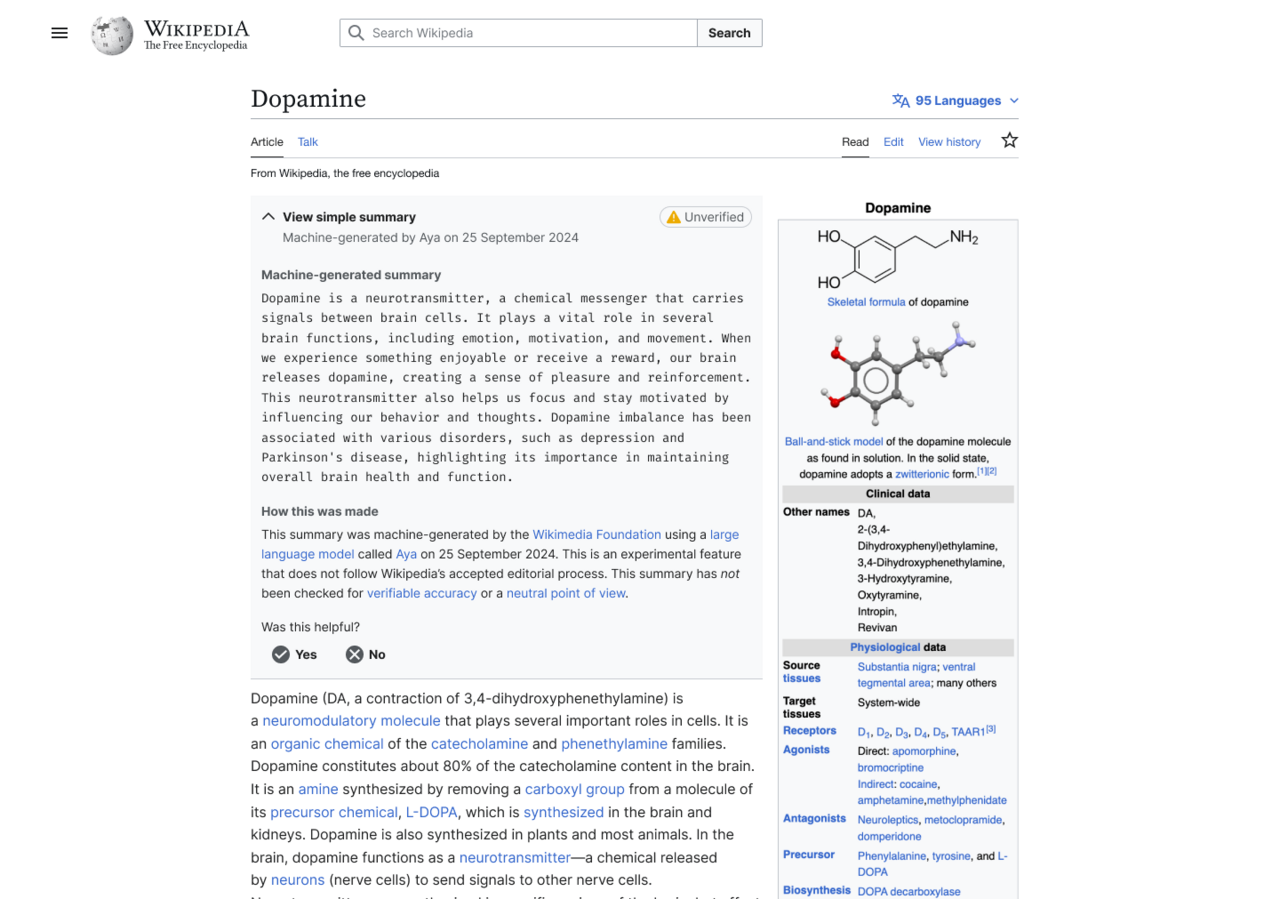
In one experiment where summaries were enabled for users who have the Wikipedia browser extension installed, the generated summary showed up at the top of the article, which users had to click to expand and read. That summary was also flagged with a yellow “unverified” label.
An example of what the AI-generated summary looked like.
Wikimedia announced that it was going to run the generated summaries experiment on June 2, and was immediately met with dozens of replies from editors who said “very bad idea,” “strongest possible oppose,” Absolutely not,” etc.
“Yes, human editors can introduce reliability and NPOV [neutral point-of-view] issues. But as a collective mass, it evens out into a beautiful corpus,” one editor said. “With Simple Article Summaries, you propose giving one singular editor with known reliability and NPOV issues a platform at the very top of any given article, whilst giving zero editorial control to others. It reinforces the idea that Wikipedia cannot be relied on, destroying a decade of policy work. It reinforces the belief that unsourced, charged content can be added, because this platforms it. I don't think I would feel comfortable contributing to an encyclopedia like this. No other community has mastered collaboration to such a wondrous extent, and this would throw that away.”
A day later, Wikimedia announced that it would pause the launch of the experiment, but indicated that it’s still interested in AI-generated summaries.
“The Wikimedia Foundation has been exploring ways to make Wikipedia and other Wikimedia projects more accessible to readers globally,” a Wikimedia Foundation spokesperson told me in an email. “This two-week, opt-in experiment was focused on making complex Wikipedia articles more accessible to people with different reading levels. For the purposes of this experiment, the summaries were generated by an open-weight Aya model by Cohere. It was meant to gauge interest in a feature like this, and to help us think about the right kind of community moderation systems to ensure humans remain central to deciding what information is shown on Wikipedia.”
“It is common to receive a variety of feedback from volunteers, and we incorporate it in our decisions, and sometimes change course,” the Wikimedia Foundation spokesperson added. “We welcome such thoughtful feedback — this is what continues to make Wikipedia a truly collaborative platform of human knowledge.”
“Reading through the comments, it’s clear we could have done a better job introducing this idea and opening up the conversation here on VPT back in March,” a Wikimedia Foundation project manager said. VPT, or “village pump technical,” is where The Wikimedia Foundation and the community discuss technical aspects of the platform. “As internet usage changes over time, we are trying to discover new ways to help new generations learn from Wikipedia to sustain our movement into the future. In consequence, we need to figure out how we can experiment in safe ways that are appropriate for readers and the Wikimedia community. Looking back, we realize the next step with this message should have been to provide more of that context for you all and to make the space for folks to engage further.”
The project manager also said that “Bringing generative AI into the Wikipedia reading experience is a serious set of decisions, with important implications, and we intend to treat it as such, and that “We do not have any plans for bringing a summary feature to the wikis without editor involvement. An editor moderation workflow is required under any circumstances, both for this idea, as well as any future idea around AI summarized or adapted content.”


This was a joke, but a handful of people expressed genuine interest in reading a book that bashes oligarchs and AI, just for the sake of it.
I'm heavily anti-AI. So much so, I'm pretty sure this is why my Instagram and Threads account got zapped out of existence. Meta couldn't handle the heat every single time they posted some slop-positive buzz on their official accounts, I don't know ...
But, I run my entire website behind Anubis, and I dropped Windows completely over their introduction of spyware into their malware OS. I'm not unfamiliar with AI, I've used it. I've given it a whirl. It's a bunch of garbage built on the backs of anyone whose ever done even an ounce of creative or skilled, written work. Be it code, a personal blog, or even fiction.
And it's getting worse. Every day I see more and more people embracing generative slop, either for fun, or for a social media avatar, or "because anti-AI people are annoying." It's like a virus, a pandemic. A pandemic that's evaporating fresh water, and melting the icecaps.
The fascist elites wanted a way to extract our labor, and pilfer our pockets, and with these so-called "tools" every facet of what we call "the Arts" are being destroyed, along with the world we live in.
Search Google images, scroll through Reddit, and just look at what your parents are consuming on Facebook. This is an emergency, and patient zero has a name: Sam Altman.


Fuck AI
"We did it, Patrick! We made a technological breakthrough!"
A place for all those who loathe AI to discuss things, post articles, and ridicule the AI hype. Proud supporter of working people. And proud booer of SXSW 2024.