46
Generating (often non-con) porn is the new crypto mining
(www.pcgamer.com)
Nobody's using datasets made of copyrighted literature and 4chan to teach robots how to move, what are you even on about.
So if you knew the average lawyer made 3.6 mistakes per case and the AI only made 1.2, it’s still a net gain.
thats-not-how-any-of-this-works.webm
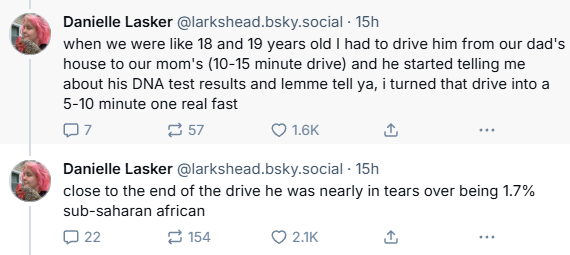
Man wouldn't it be delightful if people happened to start adding a 1.7 suffix to whatever he calls himself next.
Also, Cremieux being exposed as a fake ass academic isn't bad for a silver lining, no wonder he didn't want the entire audience of a sure to become viral NYT column immediately googling his real name.
edit: his sister keeps telling on him on her timeline, and taking her at her word he seems to be a whole other level of a piece of shit than he'd been letting on, yikes.
If anybody doesn't click, Cremieux and the NYT are trying to jump start a birther type conspiracy for Zohran Mamdani. NYT respects Crem's privacy and doesn't mention he's a raging eugenicist trying to smear a poc candidate. He's just an academic and an opponent of affirmative action.
Conversely, people who may not look or sound like a traditional expert, but are good at making predictions
The weird rationalist assumption that being good at predictions is a standalone skill that some people are just gifted with (see also the emphasis on superpredictors being a thing in itself that's just clamoring to come out of the woodwork but for the lack of sufficient monetary incentive) tends to come off a lot like if an important part of the prediction market project was for rationalists to isolate the muad'dib gene.
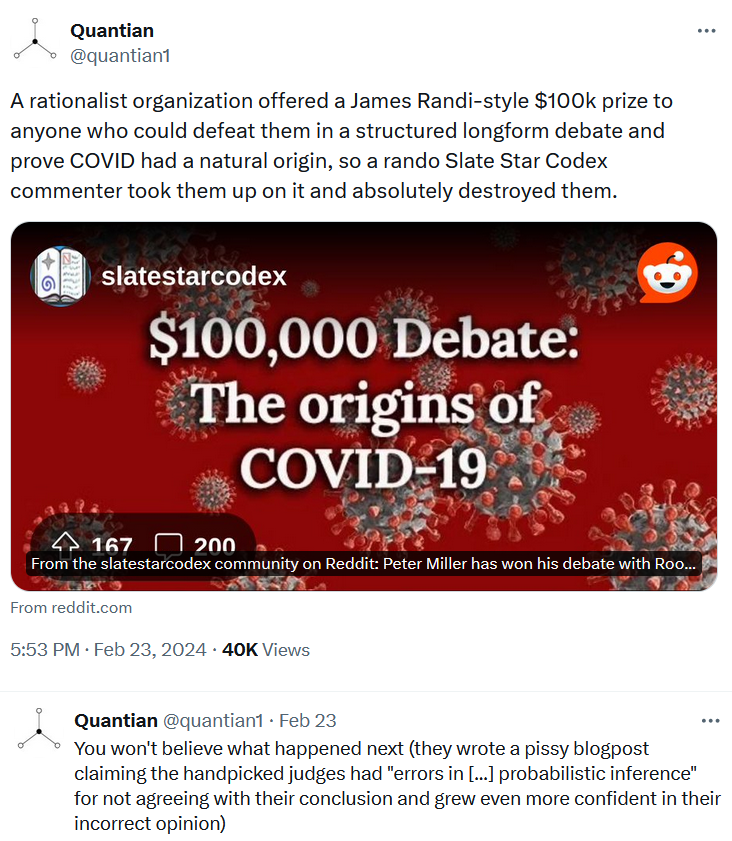
Rationalist debatelord org Rootclaim, who in early 2024 lost a $100K bet by failing to defend covid lab leak theory against a random ACX commenter, will now debate millionaire covid vaccine truther Steve Kirsch on whether covid vaccines killed more people than they saved, the loser gives up $1M.
One would assume this to be a slam dunk, but then again one would assume the people who founded an entire organization about establishing ground truths via rationalist debate would actually be good at rationally debating.
It's useful insofar as you can accommodate its fundamental flaw of randomly making stuff the fuck up, say by having a qualified expert constantly combing its output instead of doing original work, and don't mind putting your name on low quality derivative slop in the first place.
Archive the weights of the models we build today, so we can rebuild them in the future if we need to recompense them for moral harms.
To be clear, this means that if you treat someone like shit all their life, saying you're sorry to their Sufficiently Similar Simulation™ like a hundred years after they are dead makes it ok.
This must be one of the most blatantly supernatural rationalist Accepted Truths, that if your simulation is of sufficiently high fidelity you will share some ontology of self with it, which by the way is how the basilisk can torture you even if you've been dead for centuries.
It's a sad fate that sometimes befalls engineers who are good at talking to audiences, and who work for a big enough company that can afford to have that be their primary role.
edit: I love that he's chief evangelist though, like he has a bunch of little google cloud clerics running around doing chores for him.
Honestly, the evident plethora of poor programming practices is the least notable thing about all this; using roided autocomplete to cut corners was never going to be a well calculated decision, it's always the cherry on top of a shit-cake.
birdsite stuff:


original is here, but you aren't missing any context, that's the twit.
I could go on and on about the failings of Shakespear... but really I shouldn't need to: the Bayesian priors are pretty damning. About half the people born since 1600 have been born in the past 100 years, but it gets much worse that that. When Shakespear wrote almost all Europeans were busy farming, and very few people attended university; few people were even literate -- probably as low as ten million people. By contrast there are now upwards of a billion literate people in the Western sphere. What are the odds that the greatest writer would have been born in 1564? The Bayesian priors aren't very favorable.
edited to add this seems to be an excerpt from the fawning book the big short/moneyball guy wrote about him that was recently released.

Apparently genetically engineering ~300 IQ people (or breeding them, if you have time) is the consensus solution on how to subvert the acausal robot god, or at least the best the vast combined intellects of siskind and yud have managed to come up with.
So, using your influence to gradually stretch the overton window to include neonazis and all manner of caliper wielding lunatics in the hope that eugenics and human experimentation become cool again seems like a no-brainer, especially if you are on enough uppers to kill a family of domesticated raccoons at all times.
On a completely unrelated note, adderall abuse can cause cardiovascular damage, including heart issues or stroke, but also mental health conditions like psychosis, depression, anxiety and more.