145
via https://www.reddit.com/r/europe/comments/13chr5f/mentions_of_the_word_fascism_and_its_derivatives/
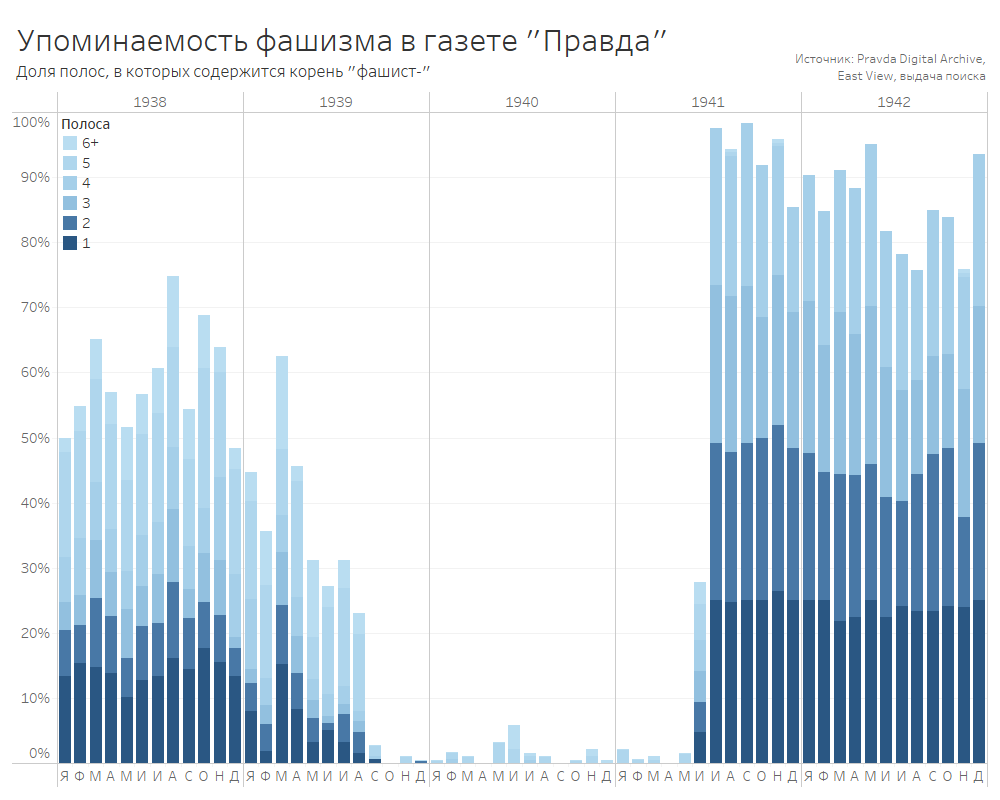
Percentage of pages mentioning "fascism" and its derivative words, from January 1938 until December 1942. Darkest blue is front page, the lightest blue is 6+ pages. Letters at the bottom are months.
Source, based on data from the Pravda Digital Archive.