Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
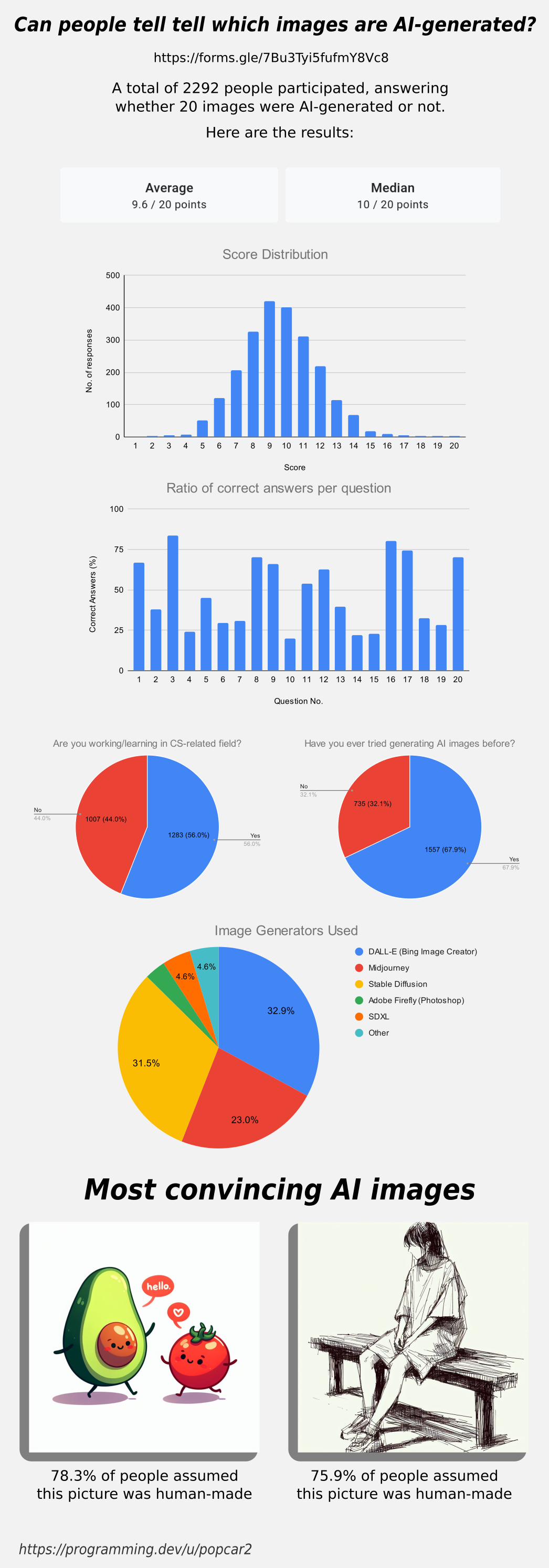
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they've gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
{kind=link}
I still don’t believe the avocado comic is one-shot AI-generated. Composited from multiple outputs, sure. But I have not once seen generative AI produce an image that includes properly rendered text like this.
Bing image creator uses the new DALL-E model which does hands and text pretty good.
generated this first try with the prompt a cartoon avocado holding a sign that says 'help me'
People forget just how fast this tech is evolving
Absolutely SDXL with loras already can do a lot of what it was thought impossible.
Image generation tech has gone crazy over the past year and a half or so. At the speed it's improving I wouldn't rule out the possibility.
Here's a paper from this year discussing text generation within images (it's very possible these methods aren't SOTA anymore -- that's how fast this field is moving): https://openaccess.thecvf.com/content/WACV2023/html/Rodriguez_OCR-VQGAN_Taming_Text-Within-Image_Generation_WACV_2023_paper.html
Yeah I'm sceptical too, what tool and prompt was used to produce this?
Its Dalle 3 its not that difficult to generate something like that using dalle 3 here's some shreks I generated as a showcase Shrek 1 inage
Shrek 2 Image
Shrek 3 Image
All of these are just generated nothing else
Huh interesting it handles text relatively well
I found the avocado comic the easiest to tell, since the missing eyebrow was so insanely out of place.
Its not that difficult to generate something like that using dalle 3 here's some shreks I generated as a showcase Shrek 1 inage
Shrek 2 Image
Shrek 3 Image
All of these are just generated nothing else
Prompt and tool links? I know there are tools that try to pick out label text in the prompt and composite it after the fact, but I don’t consider this one-shot AI generated, even if it’s a single tool from the user’s perspective.
Its Dalle 3 like I said. As far as in aware Dalle 3 doesn't do that since the text isn't always perfect still. Can't really provide prompts since its been a bit, and the history on it isn't great, but I was just mostly shrek in x style and saying "x" do mind you Dalle is very heavily censored now, so you're now unlikely to be able to recreate that.
It's on - https://bing.com/create