this post was submitted on 08 Jul 2024
858 points (96.8% liked)
Science Memes
10694 readers
3374 users here now
Welcome to c/science_memes @ Mander.xyz!
A place for majestic STEMLORD peacocking, as well as memes about the realities of working in a lab.

Rules
- Don't throw mud. Behave like an intellectual and remember the human.
- Keep it rooted (on topic).
- No spam.
- Infographics welcome, get schooled.
Research Committee
Other Mander Communities
Science and Research
Biology and Life Sciences
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- !reptiles and [email protected]
Physical Sciences
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
Humanities and Social Sciences
Practical and Applied Sciences
- !exercise-and [email protected]
- [email protected]
- !self [email protected]
- [email protected]
- [email protected]
- [email protected]
Memes
Miscellaneous
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
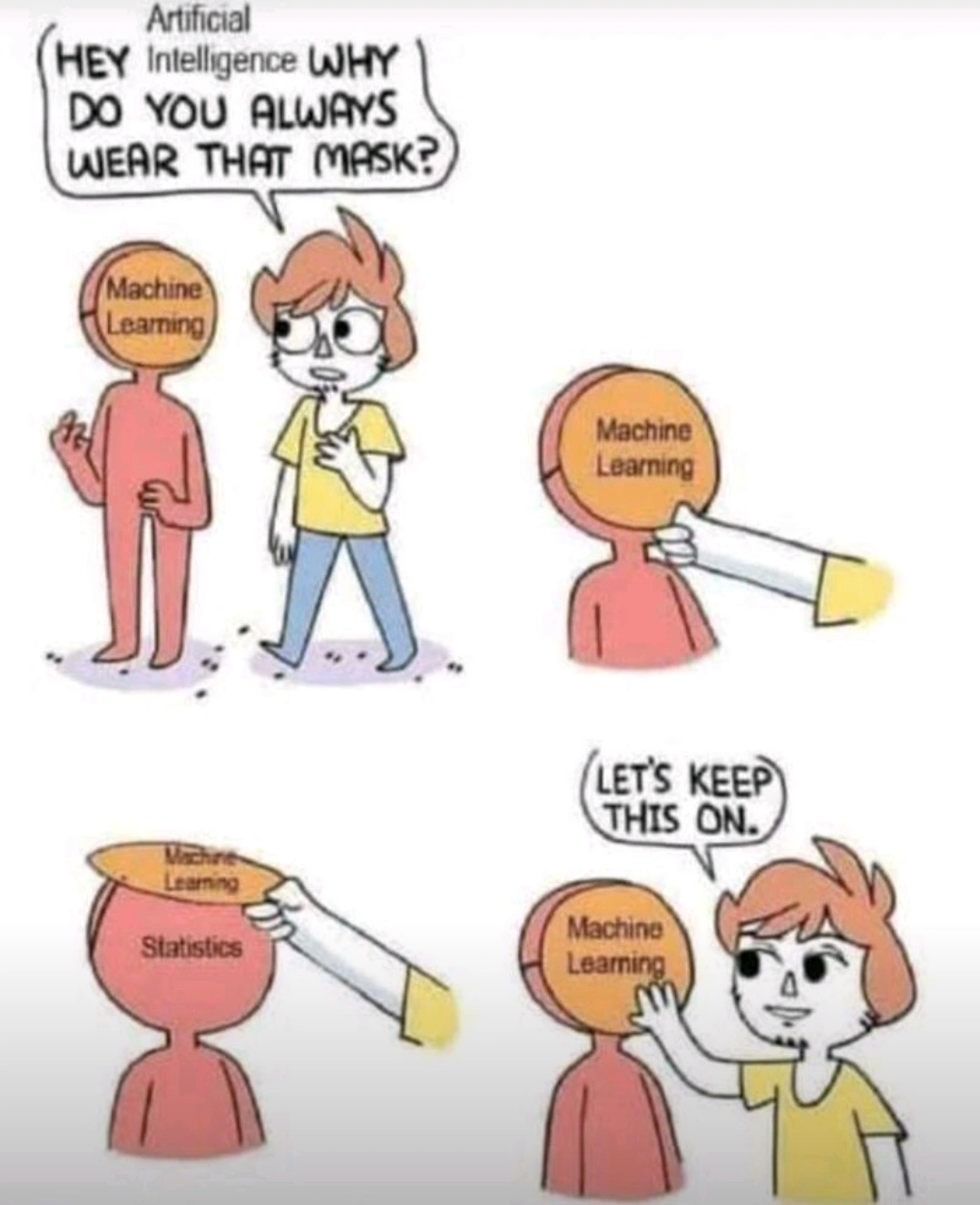
I think saying machine learning is just statistics is a bit misleading. There’s not much statistics going on in deep learning. It’s mostly just “eh, this seems to work I dunno let’s keep doing it and see what happens”.
Yeah, no.
Well, eventually the thing you’re working on falls out of fashion in place for the next trendy thing.
While I don't disagree with that statement at all, I honestly have no idea how it's related to my comment (probably because I'm an idjit)
But... you have to create criteria for what qualifies as success vs failure, and it's a scale, not a boolean true/false. That's where the statistics come in, especially if you have multiple criteria with different weights etc.
The criteria is a loss function, which can be whatever works best for the situation. Some might have statistical interpretations, but it’s not really a necessity. For Boolean true/false there are many to choose from. Hinge loss and logistic loss are two common ones. The former is the basis for support vector machines.
But the choice of loss is just one small part in the design of a deep learning model. Choice of activation functions, layer connectivity, regularization and optimizer must also be considered. Not all of these have statistical interpretations. Like, what is the statistical interpretation between the choice of Relu and Leaky Relu? People seemed to prefer one over the other because that’s what worked best for them.