1
2
3
4
5
9
It’s Not Intelligent If It Always Halts: A Critical Perspective on Current Approaches to AGI
(www.lifeiscomputation.com)
6
7
8
9
10
11
12
13
14
15
16
8
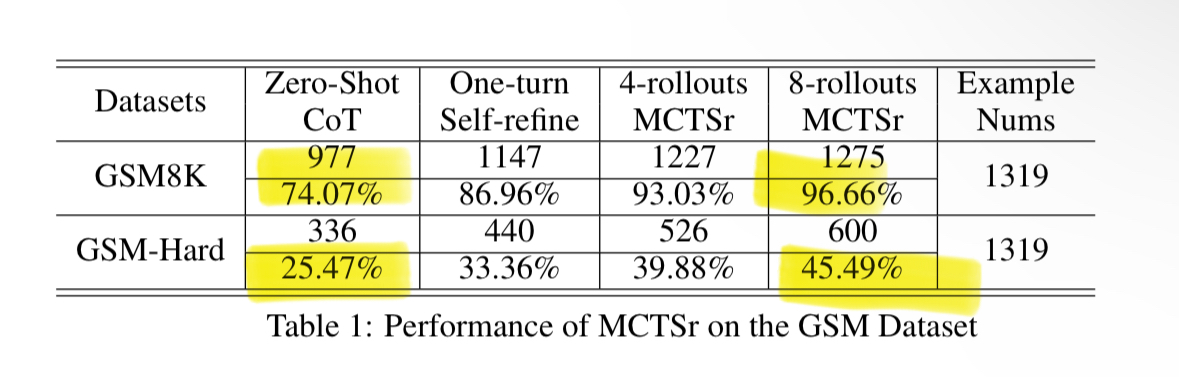
17
18
19
20
21
22
23
Hey guys,
I have been experimenting with self-supervised visual learning a bit. Until now I have only ever used U-Nets and related architectures.
No matter what specific task, images or other parameters I changed I always encountered these stains on my output-images (here marked with green), although sometimes more, sometimes less.
Now I wondered if anybody could tell me where they came from and how I could prevent them?
In the attached picture the input (left) and target (right) are the same, so that I can be sure these stains do not come from a badly designed learning task, yet they still appear (output is the middle image).
Thanks in advance and all the best :D
Edit: added line breaks

24
0
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
(hidiffusion.github.io)
25
view more: next ›