Selfhosted
39650 readers
299 users here now
A place to share alternatives to popular online services that can be self-hosted without giving up privacy or locking you into a service you don't control.
Rules:
-
Be civil: we're here to support and learn from one another. Insults won't be tolerated. Flame wars are frowned upon.
-
No spam posting.
-
Posts have to be centered around self-hosting. There are other communities for discussing hardware or home computing. If it's not obvious why your post topic revolves around selfhosting, please include details to make it clear.
-
Don't duplicate the full text of your blog or github here. Just post the link for folks to click.
-
Submission headline should match the article title (don’t cherry-pick information from the title to fit your agenda).
-
No trolling.
Resources:
- awesome-selfhosted software
- awesome-sysadmin resources
- Self-Hosted Podcast from Jupiter Broadcasting
Any issues on the community? Report it using the report flag.
Questions? DM the mods!
founded 1 year ago
MODERATORS
1
2
3
4
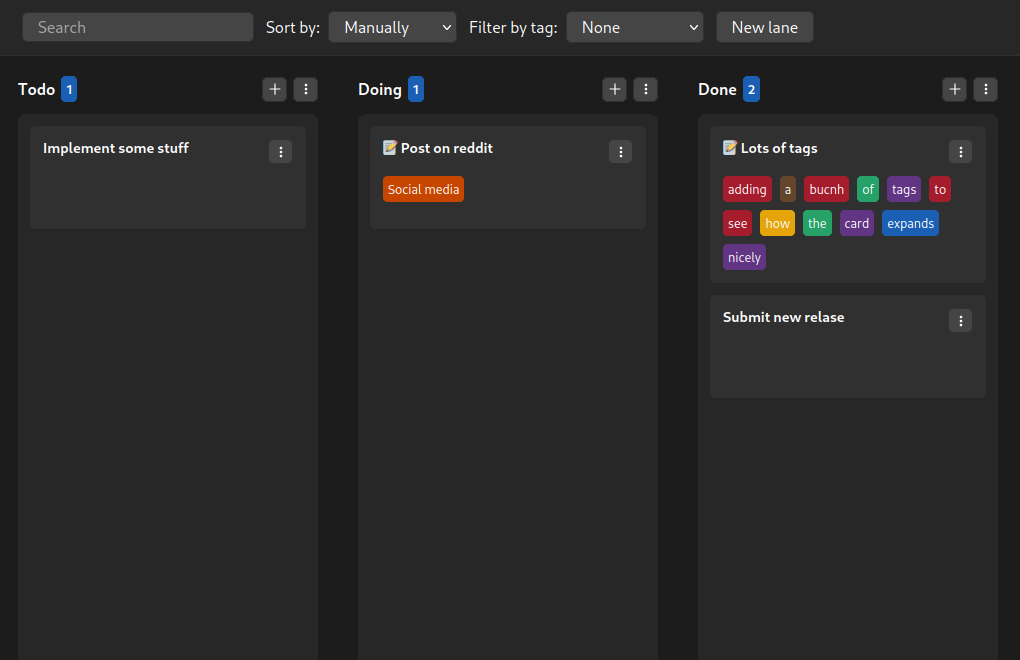
Hey guys, version 2.5.3 of Tasks.md just got released!
This release is actually pretty small, as I focused a lot on resolving technical debt, fixing visual inconsistencies and improving "under the hood" stuff. Which I will continue to do a little bit more before the next release.
For those who don't know, Tasks.md is a self-hosted, Markdown file based task management board. It's like a kanban board that uses your filesystem as a database, so you can manipulate all cards within the app or change them directly through a text editor, changing them in one place will reflect on the other one.
The latest release includes the following:
- Feature: Generate an initial color for a new tags based on their names
- Feature: Add new tag name input validation
- Fix: Use environment variables in Dockerfile ENTRYPOINT
- Fix: Allow dragging cards when sort is applied
- Fix: Fix many visual issues
Edit: Updated with the correct link, sorry for the confusion! The fact that someone created another application with the same name I used for the one I made is really annoying
5
6
7
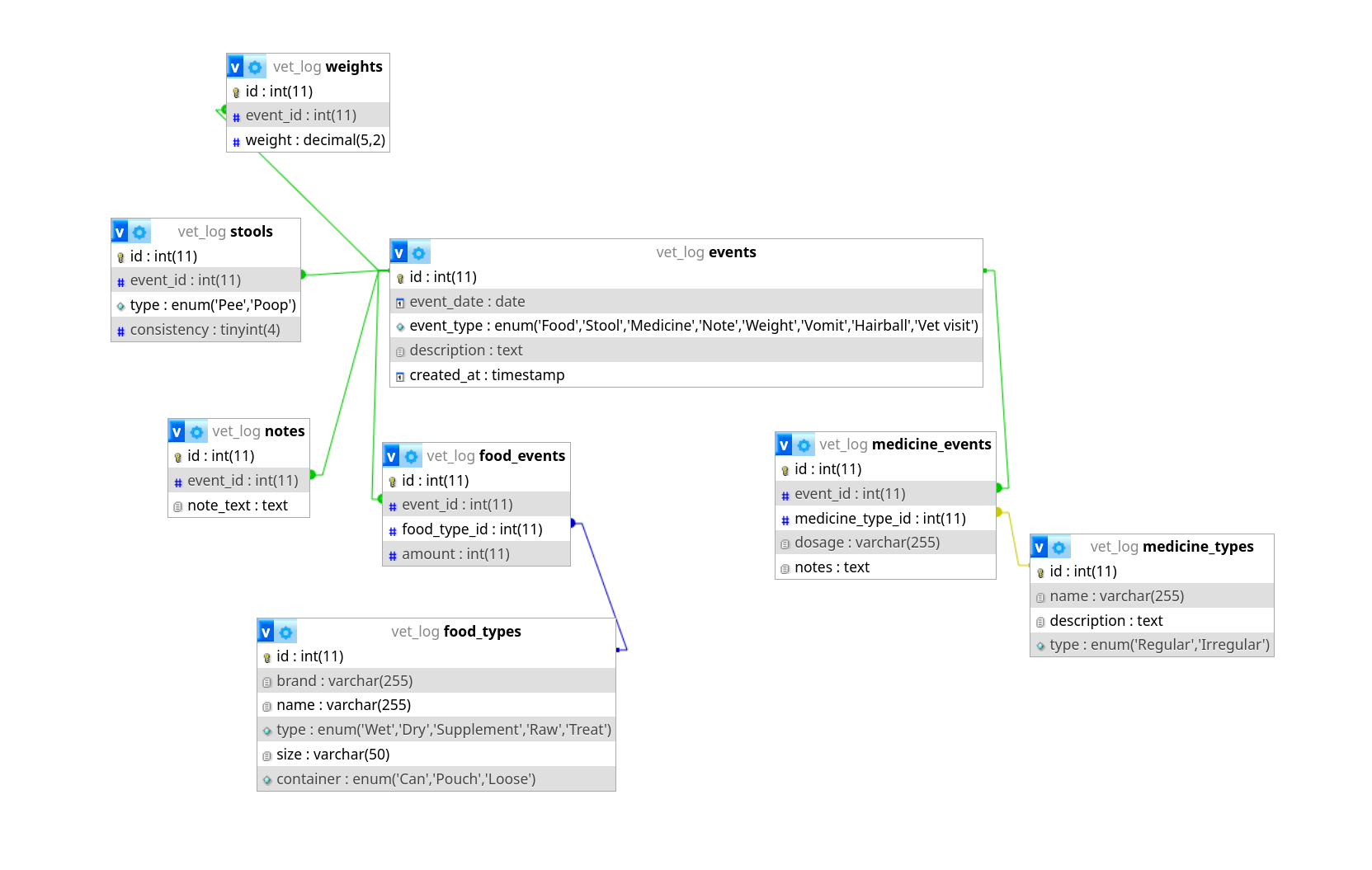
I need to record information about what my cat eats and does, as she might have a food allergy and I need to track down what it is.
So I am after some kind of a user friendly locally hosted database (maybe via some kind of app), preferably Linux friendly.
It would be nice if it had similar relationships to the added image, some kind of relational DB that I can fill with data. But essentially I need to have a bunch of lookup tables to return some data specific to difference events.
Its a bit of a pain (and takes time) to have to write an entire webapp to manage all this from scratch, that's why I am looking for some kind of user friendly GUI way to do it. Surely there must be some kind of relational database managing "application" that lets you set up some lookup tables and enter data in a nice and easy GUI way to do it? sqllitebrowser doesn't count as it doesn't handle linked tables in a nice way (would be nice if its friendly for my wife to use) :)
Cheers!
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
view more: next ›